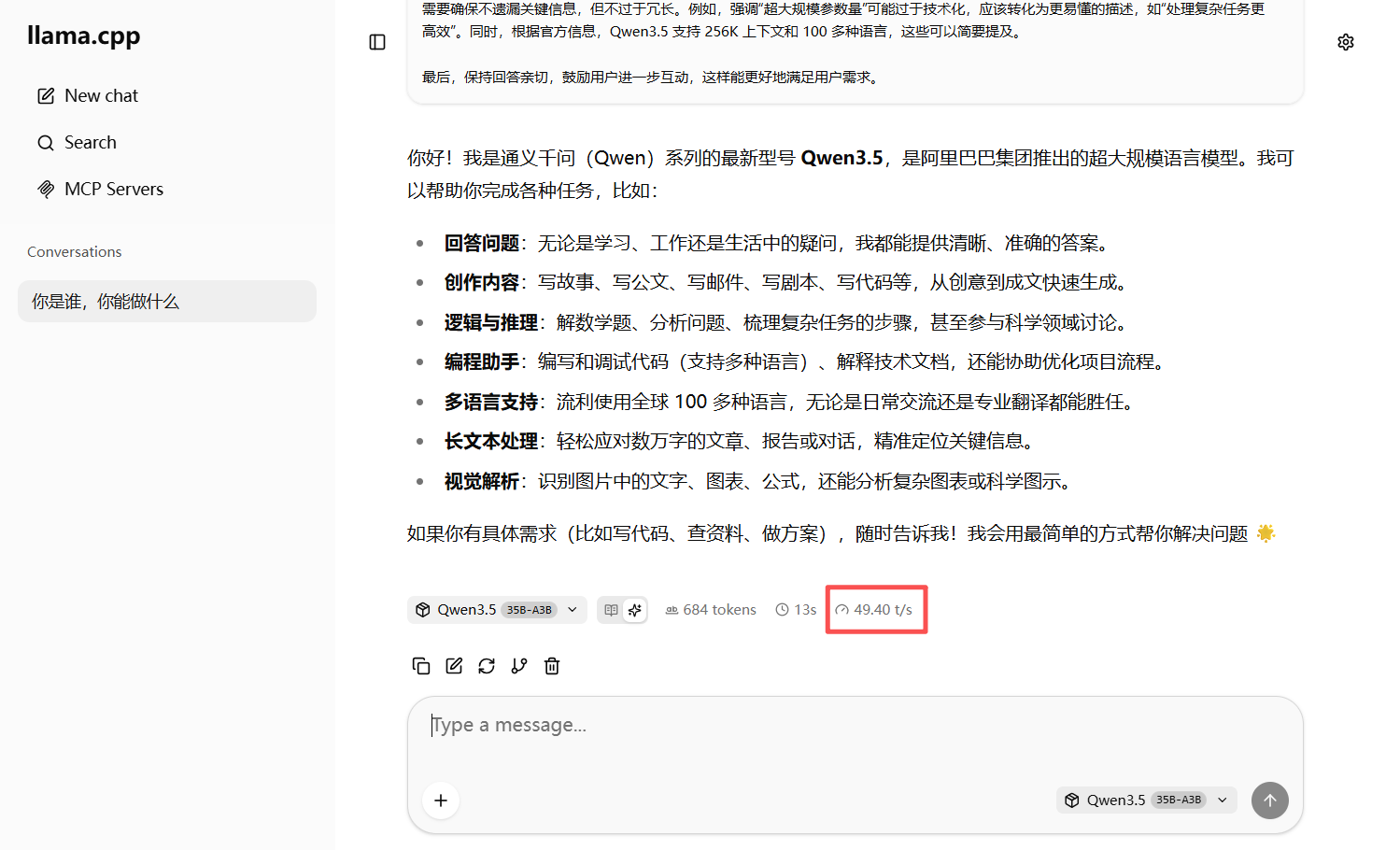
在 RTX 3060 12GB 显存 + 16GB 系统内存 的机器上,用 llama.cpp 加载 GGUF 格式的 Qwen3.6-35B-A3B,实测可以达到约 40~51 tokens/s 的生成速度。同一套硬件上,它比 Qwen3.5-9B、Qwen3.5-27B 等稠密模型还要快一截——乍听反直觉,但放在 MoE(混合专家) 的设定里就很好理解:每次推理只激活部分专家,实际参与矩阵乘法的参数量远小于「标称总参数量」,运算量相对可控;总参数量大主要带来 模型体积大、磁盘占用高,并不必然等于「每一步都更慢」。当然,这种配置下 显存与内存基本会被吃满,属于把机器榨到极限的玩法;若仍偶发 OOM,可以适当 加大交换分区(swap) 作为保险。若内存紧张、频繁换页导致卡顿,可以换 更低比特的量化、或 降低最大上下文长度——在 3060 + 16G 内存上能跑到 51 t/s 量级的 35B-A3B,还要啥自行车。
下文记录 Linux 从编译到服务化、以及 Windows 预编译包跑起来的要点,便于复现与调参。
一、环境准备与编译(Linux + CUDA)
使用 llama.cpp 运行 GGUF 模型。在 Linux 上需要先装好 编译工具链 与 CUDA 开发包(版本需与驱动匹配),然后:
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release -j8
编译完成后,可执行文件位于 llama.cpp/build/bin/ 目录下。
二、模型下载(ModelScope)
下载 Unsloth 提供的 Qwen3.6-35B-A3B GGUF 合集:
https://www.modelscope.cn/models/unsloth/Qwen3.6-35B-A3B-GGUF/files 下载 bartowski 提供的 FINAL-Bench_Darwin-35B-A3B-Opus GGUF 合集:
https://www.modelscope.cn/models/bartowski/FINAL-Bench_Darwin-35B-A3B-Opus-GGUF 基模型来自 FINAL-Bench/Darwin-35B-A3B-Opus ,其将原 Qwen3.5-35B-A3B 与 Jackrong/Qwen3.5-35B-A3B-Claude-4.6-Opus-Reasoning-Distilled 融合而来,调用工具稳定性的提升,是继承Opus蒸馏版模型的优点之一
下载 Jackrong 提供的opus蒸馏版 Qwopus3.6-35B-A3B-v1-GGUF 合集:
https://www.modelscope.cn/models/Jackrong/Qwopus3.6-35B-A3B-v1-GGUF/fileshttps://www.modelscope.cn/models/Jackrong/Qwopus3.6-35B-A3B-v1-GGUF/files
量化命名怎么读
UD:一类量化方案,通常 精度相对更好(具体以官方说明为准)。
Q 后面的数字:量化比特数(如 Q4、Q3、Q2),数字越大,量化比特数越多,精度越高,但体积越大,推理速度越慢。
IQ、NL:在 较低比特 下往往仍能保持尚可的效果,内存占用更小,但 推理速度通常更慢。
K:量化方法/家族标识。
S / M / L / XL / XXL:小、中、大、极大、超大——后缀越大,一般效果越好、占用也越大。
若要在资源有限的机器上 效果与速度兼顾,Q4_K_M 往往是常见折中;具体仍以你机器上的实测为准。
多模态:mmproj
mmproj-F32.gguf/mmproj-F16.gguf/mmproj-BF16.gguf:视觉投影权重,用于 图像/多模态。需要多模态时在启动参数里 指定
mmproj;纯文本可 不写该参数。精度大致 F32 > BF16 > F16(更好精度通常伴随更大体积与更高负载)。
三、推荐启动方式:llama-server + INI 预设
多模型、按模型单独配置时,使用 --models-preset 指向 INI 格式 的配置文件较方便。
示例命令(请把 --api-key 换成你自己的 随机长字符串):
./build/bin/llama-server --host 0.0.0.0 --api-key <你的随机长密钥> --metrics --parallel 2 -fit on -fitt 768 --models-preset <llama_server_models.ini文件路径>
INI 参考(含实测备注与多组注释)
下面是一份可直接改模型路径使用的模板;文中 c = 32768 与 c = 102400 表示 上下文长度,更长上下文通常需要 更多内存/显存。量化行前的注释里保留了 占用与 t/s 的实测笔记,可按需取消注释切换。
version = 1
[*]
c = 32768
flash-attn = on
batch-size = 512
ctk = f16
ctv = f16
context-shift = true
[FINAL-Bench_Darwin-35B-A3B-Opus]
load-on-startup = true
; 20.59GB 效果好 45.11 t/s
;model = /home/acai/workspace/llm_models/FINAL-Bench_Darwin-35B-A3B-Opus/FINAL-Bench_Darwin-35B-A3B-Opus-Q4_K_S.gguf
; 18.81GB 省显存,效果与Q4_K_S相似 47.55 t/s
;model = /home/acai/workspace/llm_models/FINAL-Bench_Darwin-35B-A3B-Opus/FINAL-Bench_Darwin-35B-A3B-Opus-IQ4_XS.gguf
; 12.07GB 省显存,速度快,效果略差 IQ4_XS 51.06 t/s
model = /home/acai/workspace/llm_models/FINAL-Bench_Darwin-35B-A3B-Opus/FINAL-Bench_Darwin-35B-A3B-Opus-IQ2_M.gguf
mmproj = /home/acai/workspace/llm_models/FINAL-Bench_Darwin-35B-A3B-Opus/mmproj-FINAL-Bench_Darwin-35B-A3B-Opus-f16.gguf
c = 102400
; Thinking mode: General tasks
temp = 1.0
top-p = 0.95
top-k = 20
min-p = 0.0
presence-penalty = 1.5
repeat-penalty = 1.0
[Qwen3.6-35B-A3B]
load-on-startup = false
; 20.21GB 效果好 42.3t/s
;model = /home/acai/workspace/llm_models/Qwen3.6-35B-A3B/Qwen3.6-35B-A3B-UD-Q4_K_L.gguf
; 17.82GB 省显存,速度慢,效果略差 Q4_K_L 33.96 t/s
;model = /home/acai/workspace/llm_models/Qwen3.6-35B-A3B/Qwen3.6-35B-A3B-UD-IQ4_NL.gguf
; 17.49GB 省显存,速度慢,效果略差 IQ4_NL 33.56 t/s
;model = /home/acai/workspace/llm_models/Qwen3.6-35B-A3B/Qwen3.6-35B-A3B-UD-IQ4_XS.gguf
; 16.60GB 39.74 t/s
;model = /home/acai/workspace/llm_models/Qwen3.6-35B-A3B/Qwen3.6-35B-A3B-UD-Q3_K_XL.gguf
; 12.16GB 省显存,速度快,效果略差 Q3_K_XL 48.59t/s
model = /home/acai/workspace/llm_models/Qwen3.6-35B-A3B/Qwen3.6-35B-A3B-UD-Q2_K_XL.gguf
mmproj = /home/acai/workspace/llm_models/Qwen3.6-35B-A3B/mmproj-BF16.gguf
c = 102400
; Thinking mode: General tasks
temp = 1.0
top-p = 0.95
top-k = 20
min-p = 0.0
presence-penalty = 1.5
repeat-penalty = 1.0
; Thinking mode: Precise coding tasks (e.g. WebDev)
;temp = 0.6
;top-p = 0.95
;top-k = 20
;min-p = 0.0
;presence-penalty = 0.0
;repeat-penalty = 1.0
;chat-template-kwargs = '{"enable_thinking":false}'
; Instruct (non-thinking) mode: General tasks
;temp = 0.7
;top-p = 0.8
;top-k = 20
;min-p = 0.0
;presence-penalty = 1.5
;repeat-penalty = 1.0
; Instruct (non-thinking) mode: Reasoning tasks
;temp = 1.0
;top-p = 0.95
;top-k = 20
;min-p = 0.0
;presence-penalty = 1.5
;repeat-penalty = 1.0
启动成功后,浏览器打开 http://127.0.0.1:8080,用 Web UI 测试;请求里的 API Key 需与 --api-key 一致。
四、用 systemd 托管(可选)
示例 llama.service(路径与用户名请改成你的环境):
[Unit]
Description=llamacpp
After=network.target
[Service]
Type=simple
Restart=on-failure
RestartSec=5s
ExecStart=/home/acai/workspace/llama.cpp/build/bin/llama-server --host 0.0.0.0 --api-key <你的随机长密钥> --metrics --parallel 2 -fit on -fitt 768 --models-preset <llama_server_models.ini文件路径>
WorkingDirectory=/home/acai
User=acai
[Install]
WantedBy=multi-user.target
建议把 --api-key 换成强随机密钥,并配合防火墙、反向代理等措施限制访问。
五、mmap 与内存行为(Linux)
Linux 下 llama.cpp 默认使用 mmap 映射模型文件:默认 不会一次性把整份权重拷进 RAM,而是 按需从磁盘映射读取。若你希望 启动时预加载到内存(换取更稳定延迟、但占用更高),可加 --no-mmap(需结合自身内存与是否易 OOM 权衡)。
六、Windows:预编译包直接跑
无需本地编译时,可到 Release 页下载 带 CUDA 的 Windows 压缩包,例如:
按你的 CUDA 版本选择 bin-win-cuda-13.1-x64.zip(或 cuda12 等对应包),并下载匹配的 cudart-llama-bin-...zip,解压到同一目录后即可运行。命令参数与 Linux 思路一致;若不用 INI 多模型预设,也可单模型直开,例如:
llama-server.exe -c 102400 --temp 1.0 --top-p 0.95 --top-k 20 --min-p 0.00 -m C:\Users\acai\Downloads\Qwen3.6-35B-A3B-UD-Q4_K_L.gguf --alias Qwen3.6-35B-A3B-UD-Q4_K_L --metrics --mmproj C:\Users\acai\Downloads\mmproj-BF16.gguf --context-shift --parallel 1
--models-preset 指向 INI 时,适合 多模型并存 且 按模型分别写参数;单条命令则适合 只挂一个模型 的快速验证。
七、小结
3060 12G + 16G 内存 跑 Qwen3.6-35B-A3B 的 GGUF,在合适量化与上下文设置下,40~50 t/s 是可期的;MoE 激活参数少 带来 更小的有效计算量,这是它比部分更小稠密模型 更快 的关键之一。
显存 + 内存 会吃得很满,swap 能缓解尖峰 OOM;若 频繁换页,优先 降量化比特 或 缩短最大上下文。
长上下文(如 c=102400) 比 c=32768 更吃资源,调参时务必与硬件对齐预期。

